Self-host GPU Continuous Integration with Azure Piplines and Docker!
Introduction
The IBM-ILLINOIS Center for Cognitive Computing Systems Research (C3SR) generates a lot of GPU-related code, and for a while we have been looking for a way to run some automated tests as part of a continuous integration flow. Most of our projects currently use Travis-CI, and the extent of GPU support is to install the CUDA command-line tools and libraries into a CI image, and build the GPU code. Since the workers hosted by travis do not have GPUs, it is not possible to actually execute any GPU code or the majority of the CUDA runtime during a CI job, and therefore not possible to do any real testing of GPU code.
As a high-performance computing research center, we have a variety of GPU hosts sitting around, ripe for use as self-hosted GPU testing boxes for an existing CI service.
System Architecture
With that in mind, I began to search around for a solution that would allow us to test GPU code, with the following goals:
- Free in terms of money and cheap in terms of time: at a university research center, getting money for some random infrastructure experiment is less than straightforward, and my primary job is to do research, not manage devops infrastructure.
- Integrated with Github: my code lives on github right now, and most of the other C3SR code does as well.
- Able to access large datasets: the test code may need to run on real-world datasets to confirm that each change is correct.
I am most familiar with Travis-CI, which does not offer GPU boxes. Their self-hosting is under the Travis CI Enterprise umbrella, and hidden behind a contact email. I took a brief look at CircleCI, which does provide GPU boxes at higher pricing tiers. It also allows for self-hosting, but it seems that the free tier only allow one concurrent job. Jenkins seems to allow self-hosting, but I had never used Jenkins before.
I settled on Azure Pipelines, which has tight integration with Github, a relatively simple self-hosting setup, and many parallel jobs for public self-hosted projects. I don't want to claim it is the easiest solution, or only solution - the purpose of this post is just to describe a solution.
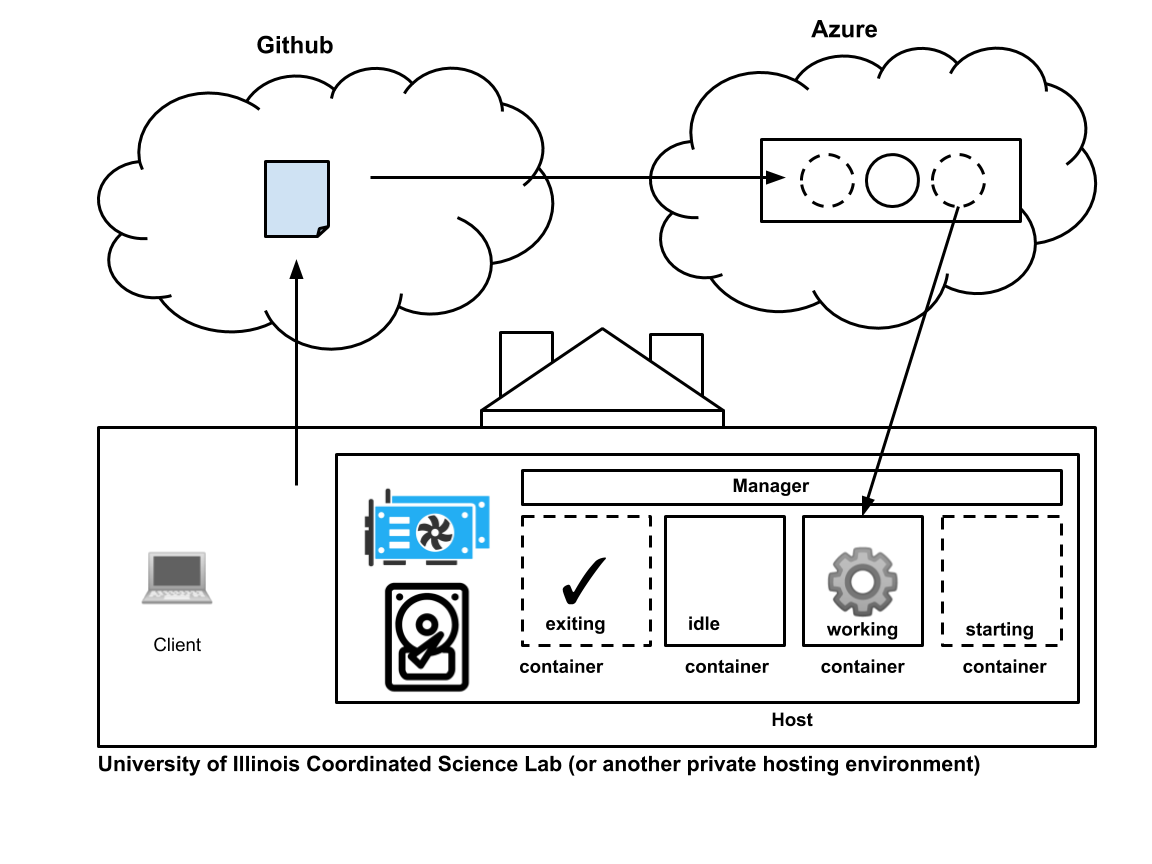 The four components of the CI system: clients who develop code, Github which hosts code, Azure Pipelines which manages the queue of CI pipelines, and the host system with a GPU where the pipelines execute in Docker containers.
The four components of the CI system: clients who develop code, Github which hosts code, Azure Pipelines which manages the queue of CI pipelines, and the host system with a GPU where the pipelines execute in Docker containers.
The entire system has four components.
- Clients. These are the users who develop GPU codes. They write their code, test it locally (I hope!), and then push it to Github.
- Github. Github needs no introduction. It maintains the modification history of the code, and tells Azure Pipelines whenever a new change has been made.
- Azure Pipelines. This is a set of software systems running in Microsoft's cloud. For our purposes, Azure Pipelines is a queue of CI jobs, and also the source of the Azure Pipelines agent binary that execute jobs on the host.
- The Host. The host is one or more GPU-enabled computers in a privately hosted computing environment (possibly behind a firewall) that run CI jobs from the Azure Pipelines queue. Docker containers on the host are used to provide a fresh environment for each job and multiplex parallel jobs into a single host. The Azure Pipelines agent runs on the host in order for the host to be tied to the Azure CI system. The agent will register themselves into the Azure Pipeline's agent pool, which we'll discuss in detail below.
Before I get any further into it, the code and documentation for hosting your own similar setup is on github
Azure Pipelines and Self-Hosted Agents
 Each container running on the self-hosted system registers itself with the custom pool on the Azure Pipelines cloud system. The self-hosted system has GPUs and large static datasets for testing. The nvidia-docker runtime allows the containers to access the host GPUs, and the large test datasets are mapped into each container as a read-only volume.
Each container running on the self-hosted system registers itself with the custom pool on the Azure Pipelines cloud system. The self-hosted system has GPUs and large static datasets for testing. The nvidia-docker runtime allows the containers to access the host GPUs, and the large test datasets are mapped into each container as a read-only volume.
For our purposes, Azure Pipelines has two important components. The first is the queue of CI pipelines, and the second are the agent pools. Each CI pipeline consists of multiple jobs, each of which can run on an agent in a specific pool. The agent pool is a list of agents that have registered themselves with Azure Pipelines. For example, if the client specifies that the job should run in the ubuntu-16.04 pool, the job will be executed by an agent somewhere in the Microsoft cloud. Azure Pipelines lets you create your own agent pools, and host your own agents!
-
Use the Azure Pipelines website to set up a new agent pool for your project. The first step of setting this up is to use the Azure Pipelines website to create an agent pool for our soon-to-exist self-hosted agents. Since these agents will have a “special” capability (GPUs), it makes sense to give them their own pool. This is described in more detail in the repository here.
-
Use the Azure Pipelines website to create a Personal Access Token This is a security token that the agent uses to connect to your specific Azure Pipelines project. This should be a secret. This is described in more detail here.
-
Set aside a GPU-enabled host system This is the computer that will run the builds and the tests. It should have an Nvidia GPU, as well as the most recent supported version of CUDA and the Nvidia driver. Older versions of CUDA will still work with the newer driver, so you can create container with old versions of CUDA for testing and they will still work with the new driver on the host. You will also need to install Docker and nvidia-docker. The agents run in docker containers to provide isolated environments for each job. You will also need to install Python3, since the manager that creates fresh containers is written in Python3. The setup is described in more detail in the repository here.
-
Start the manager The manager creates your self-hosted agents and replenishes them as they complete jobs.
python3 python/manager.py
You provide the manager with your personal access token (a very long random-looking string), the URL for your Azure Pipelines project (something like https://dev.azure.com/c3srdev), and the name of your pool. The manager will attempt to use nvidia-docker to run the highest supported CUDA agent that it can find from the cwpearson/azure-cuda-agents Docker Hub repository. If that fails, you can specify a docker image to use with the -d option. More information is provided here.
You should be able to see your agents appear under the Agent Pool on the Azure pipelines website after a few seconds.
##Design of the Self-Hosted Agents
The agent is responsible for
- listening on a specific azure pipelines pool
- accepting a single job
- execute that job in a clean environment
- accessing large datasets stored on the host
Azure Pipelines describes how to run a self-hosted agent on Linux here https://docs.microsoft.com/en-us/azure/devops/pipelines/agents/v2-linux?view=azure-devops The short version is that you download a linux binary, provide a few configuration parameters, and let it run on the system. This binary knows how to talk to Azure and accept any pending jobs. Unfortunately, if the CI job specifies any system configuration changes, those will be persisted across runs (for example, installing packages or installing a binary to /usr/bin).
An obvious solution is to use Docker to provide an isolated throw-away environment for the agent. Azure Pipelines helpfully describes how to run a self-hosted agent in Docker here https://docs.microsoft.com/en-us/azure/devops/pipelines/agents/docker?view=azure-devops Furthermore, any large data files needed for testing can be placed on those host machines and mapped into the docker container with a read-only Docker volume. The agent in the container will accept multiple jobs, leading to the same problem as before: changes within the container will persist between jobs.
The solution I chose is to have each container only accept one job, and the host should provide a constant stream of fresh containers to consume the pipelines in the Azure Pipelines queue. Luckily, the Azure Pipelines agent has a command line flag that causes it to quit (therefore terminating the container) after accepting a single job: https://docs.microsoft.com/en-us/azure/devops/pipelines/agents/v2-linux?view=azure-devops#agent-setup
Unfortunately, that flag seems to have no effect for the self-hosted docker agent described by Azure Pipelines, but it does work in the Linux-hosted agent. So, I created a Docker container following the self-hosted linux agent model. The Docker container is also built with various nvidia/cuda Docker images as a base, which provides the CUDA runtime support that we need. The Docker agents are defined here:
Design of the Manager
Since each container exits after accepting one job, we will quickly run out of agent containers on the host. The Manager is responsible for replenishing the agent containers as they are depleted. The manager is a python script that uses the docker client API to maintain a fixed number of running containers. The manager assigns a fixed pool of names to those agents to keep from cluttering the list of agents on the Azure Pipelines website with a bunch of random names as new containers are created.
The manager maintains an internal map of agent IDs to Docker container IDs. If the container associated with a particular agent ID is not running, the manager launches a new container and internally maps it to the agent ID. The name of the container is generated from the agent ID. Each container is launched with the autremove property (like docker run --rm), so that the container deletes itself when it terminates. This prevents the host Docker runtime from being cluttered with stopped containers. Each container is also launched with a high oom_score, so that containers are preferentially terminated in low-memory situations.
Prior to startup, the manager tries to auto-detect which agent image it should use by querying the CPU architecture and installed CUDA version on the host system. If a supported agent cannot be found, you can build your own. The process is outlined in the repository
Looking Forward I currently use this system for a single project. The worker is a machine with a single 12-core Intel Xeon, 32 GB of RAM, and an Nvidia RTX 6000. If it remains stable for a while, we maybe able to move some other C3SR projects over to this system as well!
Ultimately, GPU continuous integration will fall under the capabilities of the rai project. Rai's development is currently focused on supporting requirements for courses at the University of Illinois as well as requirements for the MLModelScope project, so I decided to prototype a different system.
I anticipate that another PhD student with a similar background, following this example, could get something similar up and running in a few hours.